Deploying with Kubernetes - Namespace segregation
In Kubernetes, namespaces are a powerful concept that offers a way to partition a single Kubernetes cluster into multiple virtual clusters or, in our case, multiple environments. Kubernetes namespace segregation is used for a variety of reasons of which includes:
- divide cluster resources between multiple users
- provide a scope to names - names need to be unique inside the scope of a namespace but not across namespaces
- restrict access to different environments using RBAC (Role base access control)/namespace
- partition development landscapes
Partition development landscape
This post focuses on partition development landscape. One of the advantages that Kubernetes provides is the ability for software development teams to partition their development pipelines into standalone units to manage various environments easier and better than traditional deployment strategies. For most applications, you have dev, QA, staging, and production environments. The resulting structure is ideally suited to Kubernetes namespaces. Each environment or stage in the pipeline becomes a unique namespace.
The deployment process using partition development is best represented by the below flowchart:
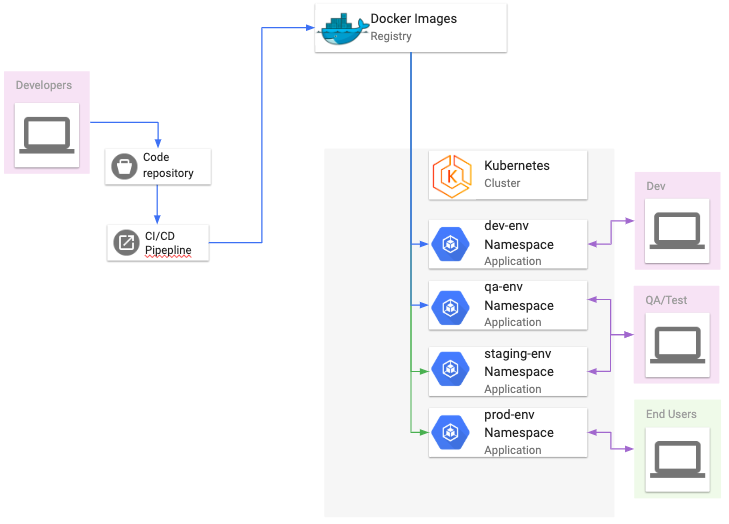 Developers commit the source code to a code repository, CI/CD pipeline jobs are then run to test/build/push the Docker images to a Docker Images Registry service and then a pipeline job that uses
Developers commit the source code to a code repository, CI/CD pipeline jobs are then run to test/build/push the Docker images to a Docker Images Registry service and then a pipeline job that uses helm or kubectl to update the Kubernetes deployment docker images is executed making this a straight forward and easy to understand deployment scenario.